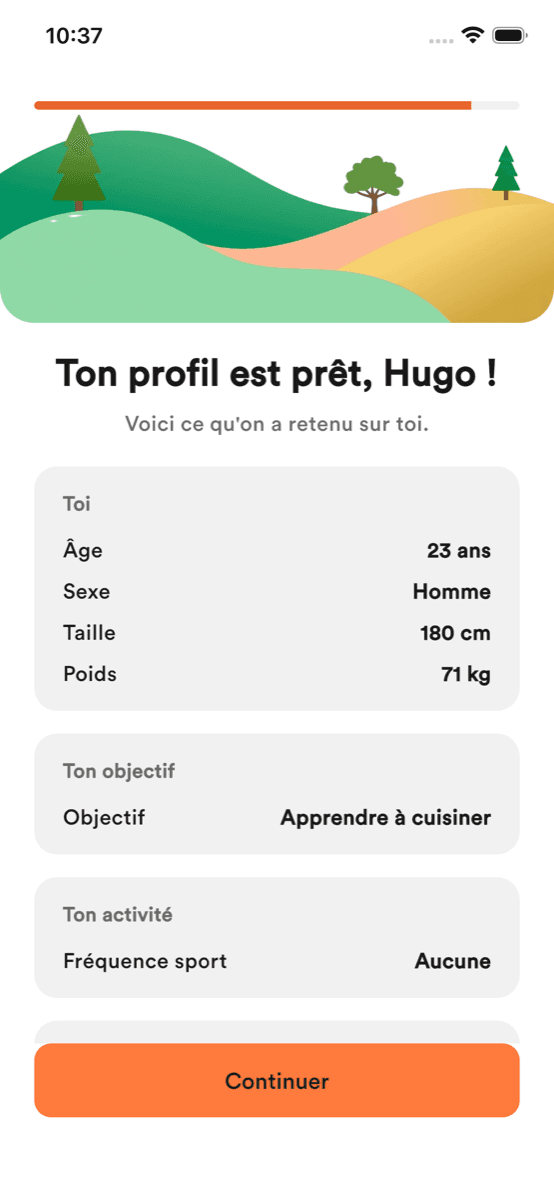
N° 01Louis Armand — Chambéry
2022
Baccalauréat
Spé maths + sciences. Les bases rigoureuses qui servent encore quand un bug résiste.
Fullstack JS — React / Nuxt / Flutter / Python
Annecy — France
Dispo alternance / Sept. 2026
J'écris des interfaces qui tiennent. Rapides, lisibles, sans approximation — du code qu'on peut relire six mois plus tard sans grimacer.
Je code depuis 2022. Une obsession : que ça tienne en production — l'UX, les détails, et le code derrière.
Je travaille au résultat, pas aux specs. Ce qui compte : l'interface répond, le code se relit, et le projet survit au prochain dev qui l'ouvre. Le reste est décoration.
Spé maths + sciences. Les bases rigoureuses qui servent encore quand un bug résiste.
Peer-learning, zéro prof. Un an à casser du C, du shell, des algos — et à apprendre à lire le code des autres.
Ma propre structure. Des projets clients livrés en Nuxt, Next, Supabase — du cahier des charges à la mise en prod.
En cours. Développement fullstack, cybersécurité, déploiement. Alternance recherchée pour prolonger la pratique en entreprise.
Trois projets. Ce qu'ils sont, ce qu'ils résolvent, ce qui a demandé de choisir.
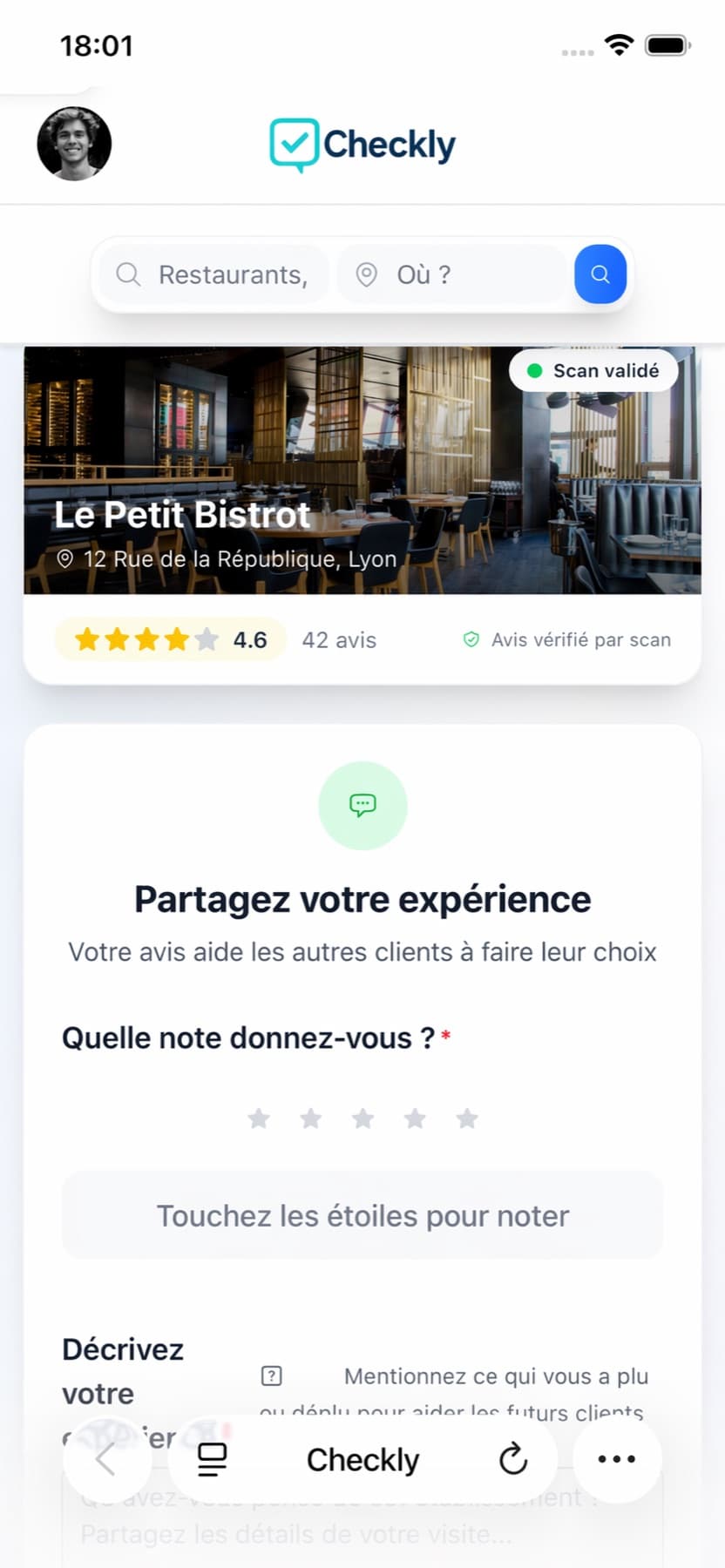
Avis anti-fraude par NFC ou QR. Un scan, un token unique. Fini les notes truquées.

Plateforme d'avis pour restaurants, commerces et hôtels. Chaque scan génère un token signé à usage unique — les liens ne se rejouent plus, les faux comptes tombent, les pros voient des retours réels.
Les avis en ligne se truquent sans effort : liens statiques rejouables, multi-comptes, bots, aucun ancrage avec le point de vente. Les pros encaissent sans moyen de trier le vrai du faux, et perdent du temps à répondre à des retours fictifs.
Chaque tag NFC ou QR délivre une URL signée avec un token dynamique, valable une fois. L'avis part — connecté via Supabase Auth ou anonyme nominatif — et le dashboard pro agrège tout en temps réel : typologie, filtres, photos, rating recalculé à la volée.
Chaque scan ouvre une URL signée, valable une seule fois. Aucun lien rejouable, aucun contournement.
Tokens régénérés à chaque passage, détection des motifs suspects, rate-limit par IP et empreinte.
Dépôt via Supabase Auth ou anonyme nominatif. Les deux identités ne se croisent jamais dans la base.
Config du commerce, suivi des avis, rating moyen, stats et réponses. Tout en temps réel.
Les horaires saisis par les pros passent en validation avant publication. Aucune donnée douteuse en ligne.
Photos ancrées à userId + businessId (et reviewId si pertinent). Catégories, filtres, recherche.
Full-stack Nuxt 3 + Supabase. Le front consomme une librairie serveur typée qui encapsule chaque accès Supabase. Les types TypeScript descendent du schéma Postgres via la CLI. Les rôles user/pro vivent dans publicMetadata Supabase Auth et sont contrôlés côté serveur sur chaque route sensible. Tables principales : users, businesses, reviews, photos, categories, features, hours, reactions, fraud_events.
Token dynamique à chaque scan — zéro lien rejouable.
Séparation stricte user / pro via Supabase Auth publicMetadata, gardée côté serveur.
Types Supabase générés par CLI, partagés entre front et serveur sans divergence.
Rating moyen et reviewCount recalculés automatiquement à l'insert et au delete.
Photos rattachées à userId + businessId, reviewId optionnel pour la traçabilité.
Horaires pro passés en validation admin avant publication.
Régénérer un token à chaque scan sans ralentir le dépôt d'avis. Il a fallu pré-signer côté serveur et paralléliser la vérification avec l'ouverture du formulaire.
Un même user peut apparaître connecté ou anonyme selon l'avis. Les deux identités coexistent dans les tables sans jamais être reliées — même pas par déduction.


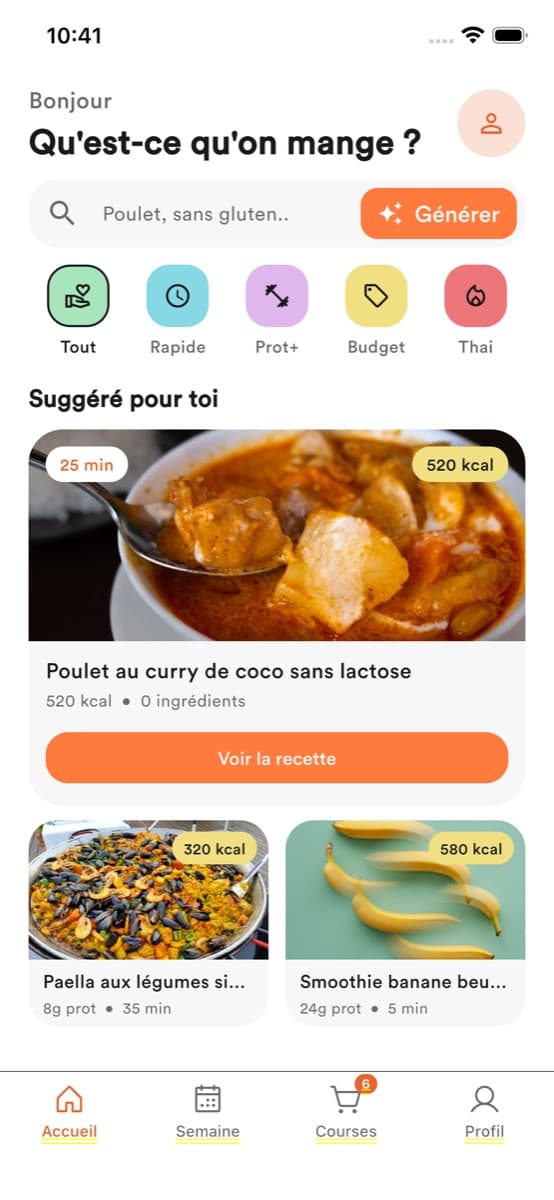
Copilote alimentaire mobile. Profil nutri, repas suggérés par LLM, planning hebdo, courses. Zéro régime imposé.
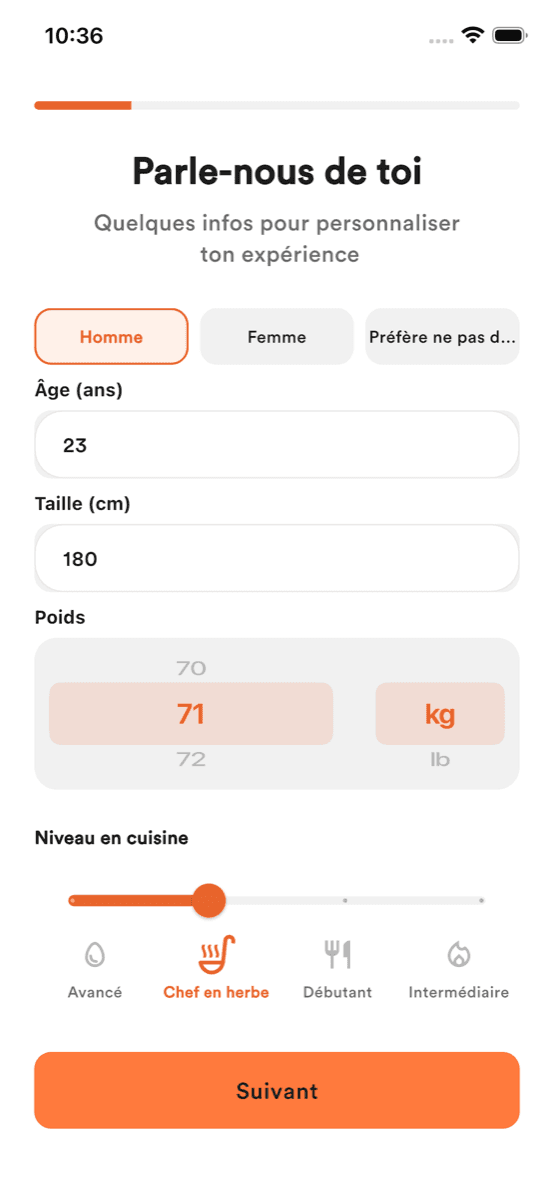
App mobile cross-plateforme (iOS, Android, Web, macOS). 15 écrans d'onboarding construisent un profil nutritionnel côté serveur (BMR, TDEE, macros), puis un backend VPS orchestre un LLM pour générer repas, recettes et planning — ajustés au profil réel, pas à un régime standard.
Manger équilibré selon son budget, ses goûts et son temps demande un vrai effort quotidien. Les apps de diète imposent des plans rigides, ignorent le contexte (courses, envie, timing) et laissent peu la main à l'utilisateur.
L'onboarding bâtit un profil complet en 15 étapes. Le serveur calcule les macros, construit les prompts, appelle le LLM, renvoie du JSON strict. Le client Flutter — MVVM + Provider — parse avec défense, affiche via GoRouter, gère l'achat via RevenueCat. Les réponses LLM sont normalisées avant d'atteindre la présentation.
Profil complet : objectif, morphologie, contraintes, activité. Le serveur calcule BMR, TDEE et macros cibles, mis en cache local pour la session.
Onglet Home — idées contextualisées (petit-déj, déjeuner, dîner, snack) selon les contraintes. Recette détaillée à la demande.
Onglet Week — grille 7 jours × repas. Re-génération case par case, export des ingrédients vers les Courses.
Les ingrédients du planning groupés par catégorie, quantités ajustées. Cochables, persistants entre sessions.
Abonnement natif sur App Store, Play Store, Web. Gate les fonctions premium (planning illimité, recettes avancées).
iOS, Android, Web, macOS. Une seule base Flutter, transitions GoRouter adaptées à chaque plateforme.
Client Flutter en trois couches : Presentation (Screens + widgets Material 3), ViewModels (ChangeNotifier Provider), Services (API, auth, billing). Domain models immutables avec fromJson/toJson défensifs. Navigation GoRouter, transitions custom par plateforme. Côté serveur, une API REST sur VPS orchestre : profil → calculs nutritionnels → prompts → LLM → normalisation JSON stricte → réponse. Credentials dans un .env chargé au boot via flutter_dotenv. RevenueCat gère les trois stores de facturation. SharedPreferences persiste profil, planning et courses en local.
MVVM strict — 8 ViewModels découplés, chacun testé isolément.
Backend VPS orchestre le LLM. Le client ne voit jamais le prompt brut, uniquement du JSON typé.
Parsing défensif : les sorties LLM arrivent parfois enrobées de markdown ou de texte parasite. Les fromJson nettoient et isolent le JSON valide avant de planter.
Domain models immutables. Toute mutation passe par copyWith, zéro surprise d'état partagé.
Calculs BMR/TDEE/macros côté serveur. Une seule source de vérité, les formules évoluent sans re-livrer l'app.
Google Sign-In v7 + Sign in with Apple. Sessions unifiées, tokens rafraîchis en silence.
Les réponses arrivent propres, parfois enrobées de ```json, parfois en texte libre avec des retours à la ligne parasites. Les fromJson nettoient et isolent le JSON valide avant qu'il atteigne la couche présentation.
iOS et Android demandent deux providers d'auth natifs (Google, Apple) et deux stores de billing. Le Web et macOS exigent une dégradation propre quand l'API native n'existe pas.
Chaque étape capture un champ ou un choix et autorise le retour arrière sans perte. Un seul ViewModel porte l'état jusqu'à la soumission finale.


Et si une opinion se calculait ? 100 citoyens synthétiques, 22 topics pondérés, moteur déporté sur Raspberry Pi. Zero LLM en prod.

Projet de recherche backend. Une API FastAPI sur Azure génère des agents, délègue le calcul à un Raspberry Pi branché au bureau d'étude via WebSocket sortant, persiste dans Supabase, et renvoie la distribution — tout se calcule, rien ne s'invente.
Demander à un LLM unique « que pense le public ? », c'est demander à une seule tête. Cher, lent, imprévisible, aucune distribution en sortie — une moyenne n'a jamais fait un sondage.
100 agents tirés sur 5 clusters politiques français : centre-gauche progressiste, centre-droite conservateur, gauche radicale, droite radicale, divers. Chaque agent porte 4 axes idéologiques et 5 axes démographiques. Le moteur détecte les topics via 22 regex, pondère les axes, applique les modificateurs démographiques, injecte un bruit gaussien seedé par paire agent × question — et sort une distribution en moins de 200 ms.
Population tirée sur gaussiennes centrées autour des cinq pôles du paysage français. Les axes démographiques — âge, éducation, classe sociale, urbain/rural — corrèlent avec les axes idéologiques, pas à l'aveugle.
Immigration, nucléaire, retraites, pouvoir d'achat, Europe, laïcité… Chaque topic est un couple (regex, poids par axe). Une question transversale matche plusieurs topics, les poids se moyennent automatiquement.
Même seed, mêmes agents, mêmes réponses. Chaque paire agent × question a son propre RNG dérivé d'un hash MD5 — indispensable pour comparer deux scénarios ou calibrer les poids sans bruit parasite.
Le moteur tourne sur un Pi physique, au bureau d'étude. Connexion WebSocket sortante vers le backend, aucun port exposé, aucune IP publique requise. Reconnexion automatique avec backoff 1 s → 60 s.
10 cas de référence tirés de sondages IFOP. Chaque modification de poids est évaluée contre ces distributions avant merge — le moteur ne dérive pas en silence.
Stance (pour/contre/mitigé), likert (échelle numérique), QCM (choix multiples). Les trois cohabitent dans un même questionnaire, agrégation automatique par type.
Deux dépôts, trois étages physiquement séparés. Le backend FastAPI vit containerisé sur un VPS Azure, derrière un Nginx qui termine le TLS et proxifie HTTP comme WebSocket (timeout 3600 s). L'API parle à Supabase — 11 tables métier, relations tracées avec CASCADE et RESTRICT réfléchis — et délègue tout le calcul de simulation à un Raspberry Pi branché au bureau d'étude. Le Pi ouvre lui-même la connexion WebSocket, pas l'inverse ; chaque appel est corrélé par un task_id UUID géré par PiWsManager. Redis porte les sessions et la canalisation realtime. Côté livraison, deux workflows GitHub Actions : le CI lint (ruff), teste (pytest, cov ≥ 90 %), build l'image Docker et push sur GHCR ; le CD, déclenché au succès du CI, SCP le compose, SSH pour pull/up --force-recreate, boucle un healthcheck 30 fois, prune les images, recharge Nginx. Dev bascule sur staging, main sur prod.
Architecture hexagonale — endpoints, services, repositories, infrastructure. Les tests injectent FakePiClient et FakeRepository, zéro accès réseau.
WebSocket sortant initié par le Pi — aucun port ouvert derrière le NAT domestique, aucun DynDNS à maintenir.
Corrélation backend ↔ Pi par task_id UUID. PiWsManager expose un call_sync aux endpoints HTTP synchrones.
Moins de 200 ms pour 100 agents × 5 questions. Zéro LLM, zéro appel externe en prod.
Deux environnements mappés sur des GitHub environments distincts — dev bascule sur staging, main sur prod.
Déploiement SSH avec healthcheck actif (30 tentatives, 2 s d'intervalle) — aucune validation avant que l'API réponde.
Le vrai travail de fond. Trouver les bons poids par axe pour chaque topic, pour que la distribution colle à celle d'un vrai sondage. Beaucoup d'allers-retours sur la polarité (réduire / renforcer / négation) et les modificateurs démographiques — calibrés contre 10 sondages IFOP de référence.
Le Pi vit derrière un NAT domestique. Contrainte : zéro port entrant, zéro IP publique, zéro DynDNS. Réponse : un WebSocket sortant permanent initié par le Pi, avec reconnexion automatique (backoff 1 s → 60 s) et corrélation des appels par task_id UUID côté backend.
Rendre le déploiement impossible à casser à la main. Pipeline : lint → tests → build Docker → push GHCR → SCP compose → SSH pull/up --force-recreate → healthcheck 30 tentatives → prune → nginx reload. Dev bascule sur staging, main sur prod, via GitHub environments distincts — aucun SSH manuel requis.
Je cherche une alternance dès septembre 2026. Un projet, une question, un simple bonjour — écris, je réponds sous 48 h.